


Data quality and data governance are closely aligned but there are some important differences between them. That said, successful data quality improvement depends on data governance. Learn how these critical data practices differ and how you can use data governance to supercharge the quality of your data.
There is a subtle difference between data governance and data quality. While data quality focuses on the state of the data itself, data governance considers how we manage and process that data.
Although they’re different disciplines, it’s difficult to ensure data quality without proper data governance. They’re so entwined that data stewards spend around 75% of their time defining standards, viewing data quality, and correcting data quality, according to Dataversity.
Because of this, it’s vital to understand the difference between the two, and how they can work together to benefit your company, and reduce risk.
In this article, we’ll cover:
- The differences between data governance and data quality
- Data quality is impossible to implement without data governance
- How data governance tools can help improve data quality
Are you struggling to fully understand how data flows from one place to another within your cloud-based or on-prem infrastructure? Download our white paper How to Build Data Lineage to Improve Quality and Enhance Trust
What is the difference between data governance and data quality?
Before we get into the nitty-gritty, let’s first look at the separate definitions of data governance and data quality.
Below is our simplified definition of data governance, but if you want to explore further you can read more in our blog post here:
Data governance is the process of organizing, securing, managing, and presenting data using methods and technologies that ensure it remains correct, consistent, and accessible to verified users.
As you can see, this definition includes data quality, but also covers things like data access and data literacy.
For a specific definition of data quality, we’ll borrow Sue Russel’s summary from her DAMA UK blog onData Quality and Data Governance Framework:
Data quality is the degree to which data is accurate, complete, timely, and consistent with your business’s requirements.
There are many factors to consider when you’re measuring data quality, and which of these are most important will depend on your company, and your priorities. Here are some data quality dimensions examples from DAMA’s Code for Information Quality:
- Compliance
- Consistency
- Integrity
- Latency
- Recoverability
It’s important to emphasize that although data quality is under the purview of data governance, it’s the responsibility of everyone in the company to maintain. Not just the data stewards.
Related Post: What is Data Quality? Dimensions & Their Measurement
Data Quality Depends on Data Governance
There are five primary factors that have contributed to the increasing urgency of data governance:
- BI & Analytics
- Compliance with Data Privacy and Financial Regulations
- Master Data Management
- Integrations
The fifth driver is data quality assurance, and it’s often misunderstood.
To some, data quality is simply a set of quality rules that ping when there is an issue, but there’s much more to it.
We’ve already mentioned that data quality is everyone’s responsibility, but it would be impossible to implement without thorough data governance.
To achieve cross-department data quality, you need to define practical and enforceable standards. This includes metadata definitions, consistent and transparent processes, data literacy, and more.
Without this consistency, any time you’re transferring data, you’re risking inaccuracies. This is especially risky when integrating with other companies and tools, or reporting on your data.
Without this consistency, any time you’re transferring data, you’re risking inaccuracies. This is especially risky when integrating with other companies and tools, or reporting on your data.
This is why data quality is as important as it’s ever been, and why it’s such a driver behind data governance.
Importance of Data Governance Tools to Ensure Data Quality
It’s all well and good to point out why it’s so important to factor data quality into your data governance, but the big question is how you’re going to maintain high data quality?
This is where software is your best friend!
You need to approach data quality holistically, rather than localized to specific systems or departments. Data governance tools do this by giving you a complete picture of your data, and all the features you need to drill into that information, and verify its quality.
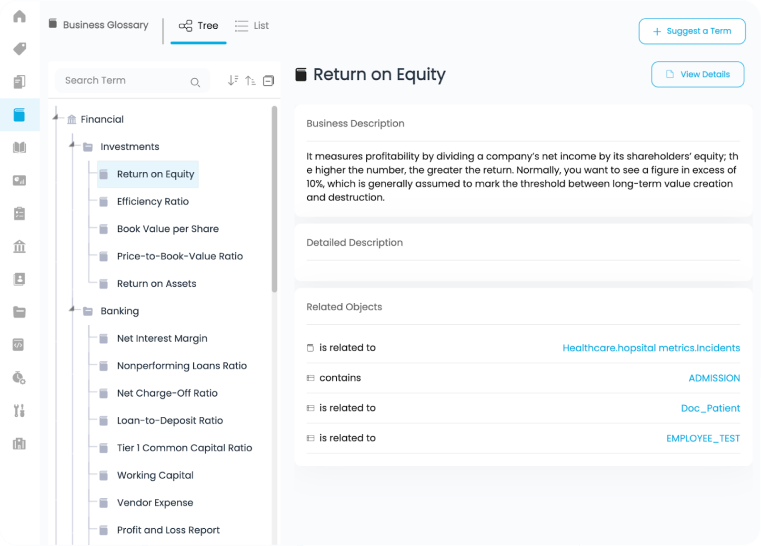
A data catalog, in particular, is a game-changing feature to look for. You can view all your data in one place, easily define relationships, and collaborate with colleagues.
This has many benefits for broader data governance work, but it’s especially useful for data quality, and maintaining high standards.
There are plenty of these tools out there, but many come with a steep learning curve. They require specialist skills, and need experience with technical languages to use.
That’s why at OvalEdge, we designed our data catalog to be as accessible as possible, meaning more people can be involved in maintaining and monitoring data quality.
We take pride in our natural language search, so your team doesn't need to spend a year learning a new language before you get value. It really is for everyone!
We take pride in our natural language search, so your team don’t need to spend a year learning a new language before you get value. It really is for everyone!
Related: Data Catalog: The Ultimate Guide
Implementing data quality with OvalEdge
We’ve already touched on the pillars of data quality, but let’s drill down more to see how you can address each one with OvalEdge.
Define
Before you do anything else, you need to define your data quality standards and capture them in OvalEdge. This will be the benchmark for your data quality, and tells everyone in the company what they should aim for.
This includes defining how data should be collected and stored, such as date and time format, or whether to include dashes in phone numbers.
Note: It’s important to define your standards in accordance with your company’s data governance strategy, to ensure consistency
Collect
Once you’ve defined your standards, you need to locate and collect all existing data quality issues within the company. This is easier said than done, but it’s much easier if you create a data literacy program.
This gives you the means to educate your colleagues on data quality, allowing them to report issues within OvalEdge as they find them. These reports should include business value, where the problem exists, what the issue is, and the priority.
To collect issues, OvalEdge presents the data catalog when decision makers are looking at the data, so they can report the problem right there. This facilitates the issue creation process.
Prioritize
When you’ve compiled a list of the issues in OvalEdge, you can focus on triaging these issues in order of priority.
This is where you get a lot of value from your quality standards, as you’ll be able to use these to validate and prioritize each issue.
It’s also important to consider business value, time to fix, and change management when deciding what should be prioritized. You can see all the key information, and carry out advanced filtering to make this process much quicker.
You need to collect various metadata, like business impact and data decision importance. OvalEdge helps you collect these data points, and prioritize the problems. If data is going to the regulators, you need to ensure there are no data quality issues.
Analyze
The next step is to dig deeper into the issues, and carry out further root cause analysis. Using the data catalog in OvalEdge, your analysts can create relationships and find where the issues stemmed from.
It’s also important to understand why the data caused an issue, and to investigate ways to prevent this from happening again in the future.
One major area of analysis is finding the root cause of the problem. OvalEdge lineage helps you easily understand where the data comes from. Analysts can then easily understand the data, and find the root cause of the problem.
Improve
Using the findings of your investigation and analysis, you then need to agree and implement improvements that will increase your data quality over time.
This can vary from manual fixes, technical solutions, master data, or even implementing new processes. The solution will vary depending on the issue, but it’s vital to define measurable objectives so you know you’re going in the right direction.
Control
The final step in this process is to write a set of rules that monitor data quality, and send alerts when issues are detected. This can’t catch brand new issues, but it will ensure you catch known issues if they happen again.
Control is about proactively checking for the errors, and data quality rules in OvalEdge help in this process. Companies can use data quality rules for the whole control process, alongside previously defined rules.
This allows you to be proactive, and not have to rely on manual discovery.
Read our Best Practices for Improving Data Quality post for a more detailed breakdown of this process.
Download Our Trending White Papers



