Data quality implementation follows a series of tried-and-tested methodologies. In this blog, we explore these methodologies, the order in which you should approach them, and how to measure their impact.
Data quality implementation follows a series of tried-and-tested methodologies. In this blog, we explore these methodologies, the order in which you should approach them, and how to measure their impact as part of a comprehensive data quality implementation plan.
We consider data governance to have three core outcomes: clear and consistent metadata, accurate data, and correct and compliant access. For these three different outcomes, we recommend three pillars: metadata governance, data quality, and privacy and access governance. In a successful data governance approach, each of these pillars works cohesively, but for this blog, we'll focus on data quality specifically, the methodologies for a successful data quality implementation plan.
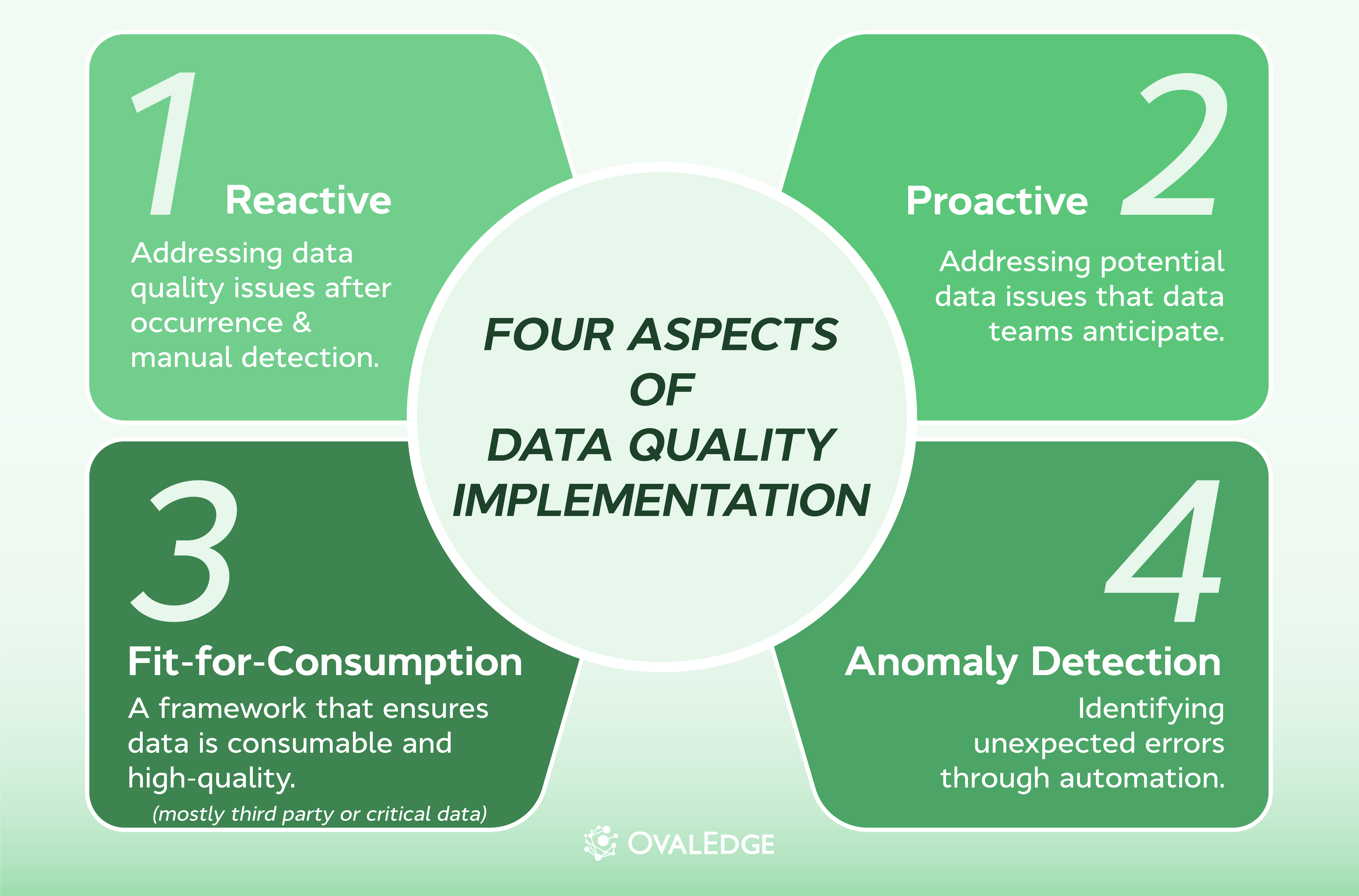
Four Aspects of Data Quality
For accurate data, organizations must implement four aspects of data quality: reactive, proactive, fit-for-consumption, and anomaly detection. These four aspects cover most data quality challenges and together define the data quality dimensions every company must monitor.
Reactive
Reactive data quality is a method of addressing data quality issues after they've already occurred. These issues are often caused by unforeseeable, adverse data events. These events happen unexpectedly, and when they do, data teams analyze them to identify the root cause and address it. Reacting to, analyzing, and correcting the root cause of adverse data events constitutes a reactive data quality implementation plan methodology.
For example, in a reactive data quality issue, an ETL job fails to update customer records accurately due to a script error, leading to outdated or missing customer information in the report. This issue is only noticed when someone spots a discrepancy, requiring immediate investigation and correction to mitigate the impact on business decisions.
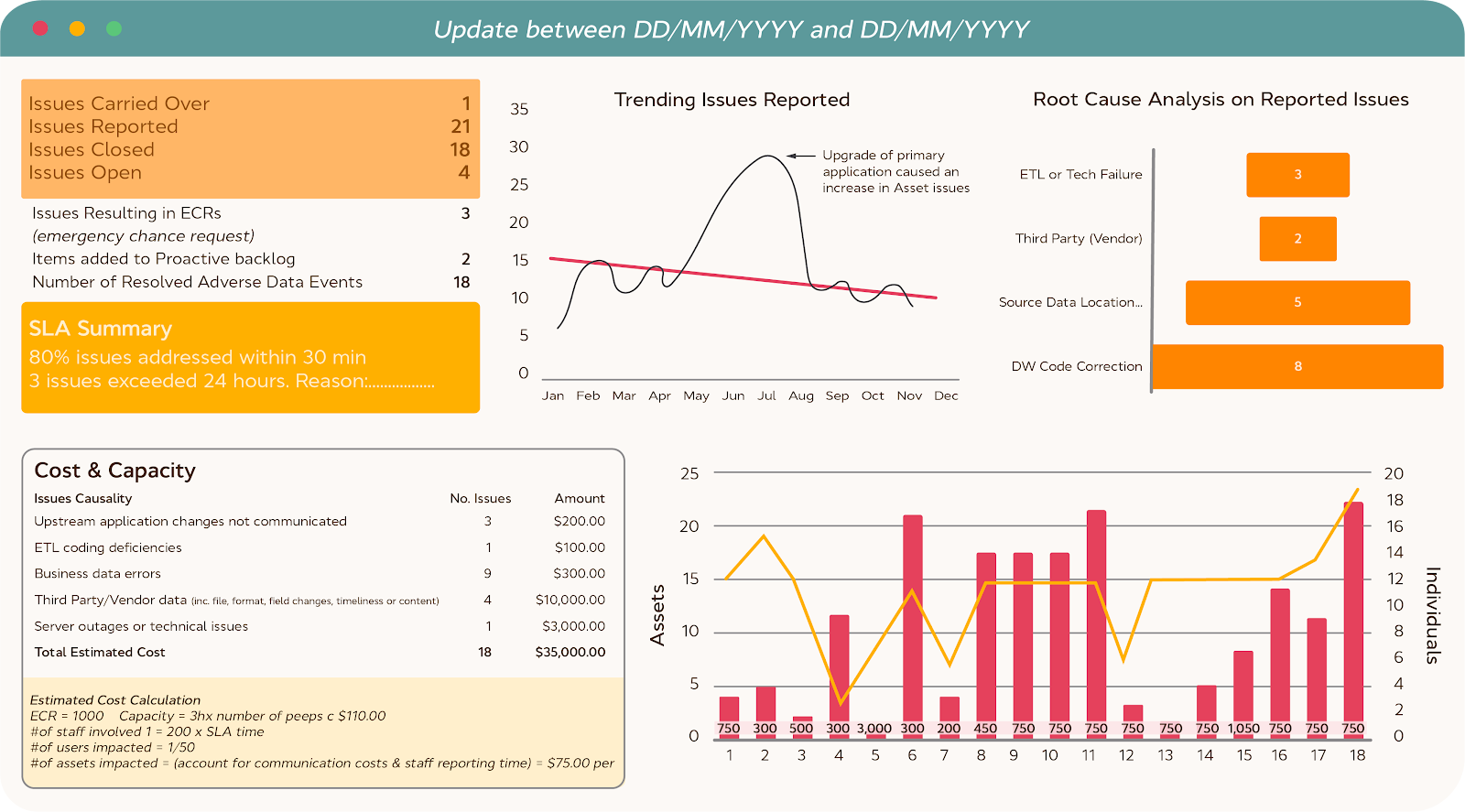
Example: Reactive Data Quality Dashboard
Proactive
Proactive data quality involves addressing potential data issues that data teams anticipate. These issues are predictable, so rules can be written to detect them as soon as they occur. A process should be in place to assign someone, usually a business user, to fix the problem when it arises.
Proactive measures are critical data quality dimensions, ensuring that governance teams catch and fix issues before they propagate downstream. Proactive data quality measures should be implemented as close to the data source as possible, reported, and remediated to prevent any negative impact on downstream assets and processes.
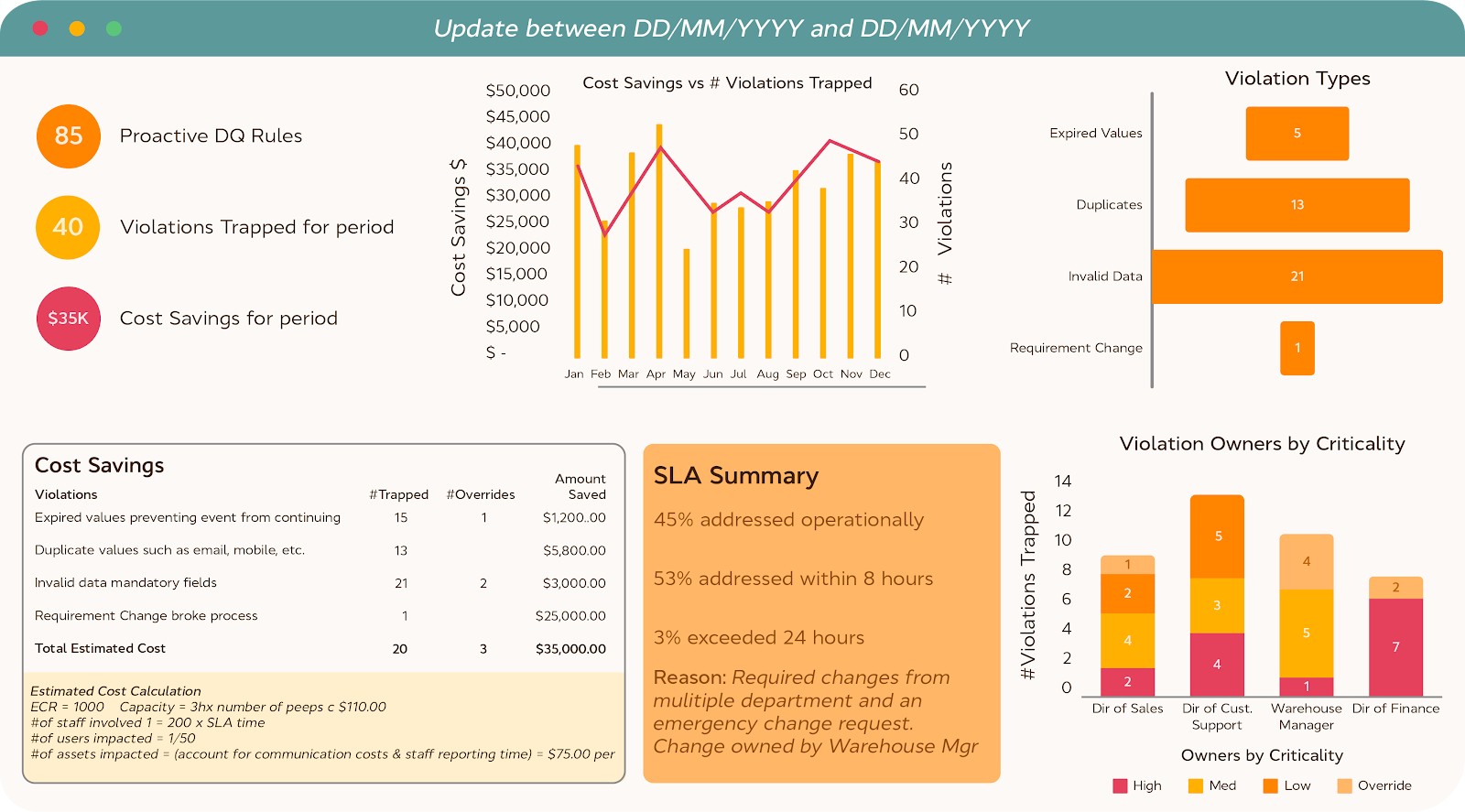
Example: Proactive Data Quality Dashboard
Fit-for-consumption
When data is received from or sent to a third-party or satellite source system, it's crucial to ensure it is consumable and high quality. To achieve this, you need to establish a fit-for-consumption data quality implementation plan.
This framework generally consists of a set of guidelines and rules that determine whether the data is fit for consumption. Data teams must consider two areas of consumption:
- Whether the data is fit for data pipeline consumption
- Whether the data is fit for consumption by third parties, such as customers or vendors
Companies typically assess this type of data quality post-integration, often in a data warehouse or self-service area. This assessment examines factors like the quality of email addresses, standards, and a data quality dimensions routine to evaluate how well these standards are met.
Anomaly detection
The challenge with proactive data quality is the requirement for prior knowledge of existing problems and the need to establish rules based on this knowledge. Anomaly detection involves identifying unexpected errors through automation.
When an anomaly is detected, an alert is generated and sent to a specific stakeholder or group of stakeholders according to a predefined framework. Upon receiving an alert, the designated stakeholder can manually address and resolve the issue or ignore it.
This method uses AI, ML, and other technologies to identify data anomalies. It adopts a shift-left approach to identify and resolve data issues promptly. The emergence of advanced AI and ML tools has significantly enhanced this aspect of data quality dimensions.
Related Post: AI Needs Domain Knowledge to Boost Data Quality
Overall, the four aspects of data quality implementation must be coordinated to reveal metrics and involve the appropriate individuals in the process.
Where to Start?
Addressing reactive data quality should be the first step in any data quality implementation plan. The focus is on understanding how well your organization reacts to data quality issues and whether there is a defined process.
It is also common to take this approach when dealing with third-party data and upstream changes that are yet to be mitigated. Gathering this information enables companies to restore their capacity and start focusing on a proactive approach.
How to Create a Roadmap for Data Quality Improvement
Just as we split data quality implementation into four aspects, the same should be done when developing an implementation roadmap that fits your business’s data quality dimensions.
Reactive
Starting with reactive data quality, a company must determine a procedure for reporting data quality issues that incorporates people, tools, and processes. Core actions include collecting the data, prioritizing the work, and analyzing and fixing the root cause.
As soon as a problem occurs, the data must be captured within a tool as a ticket, and transferred to the appropriate stakeholder who will prioritize it and then perform a root cause analysis. When the root cause is fixed, controls must be put in place to ensure the issue can be quickly dealt with if it occurs again.
Related Post: Top 8 Features of a Data Quality Tool
Using a tool enables data teams to better understand flaws in the data quality provisions in place. This means that when it comes to root cause analysis, the data is on hand to support your quality improvement efforts.
It is very important to understand which issues take precedence. To know how to prioritize data quality improvement, you need to curate reports in a way that surfaces business criticality.
Communication is also a core concern. Specifically, communicating the most important data quality issues after following a triage process that defines the root cause. This can be achieved using dedicated lineage tools and upstream impact analysis.
Proactive
Moving into proactive data quality, data teams must write a series of data quality rules that address known problems and assign a remediation process and a stakeholder to carry it out. It’s critical to track the business, particularly who owns a data quality rule, and monitor for data quality events close to the source. Now, you're transforming your data quality improvement program into a driver of value.
This process involves assigning a data center and a remediation schedule. For example, if you have an incorrect vehicle registration number for a car loan, you should have a process in place that details where to alter the document number and the person responsible for carrying out the request. Ultimately, it follows an established data quality rule with step-by-step instructions on how to mitigate the error.
Using the OvalEdge Data Quality Command Center feature, users can easily analyze how a data quality rule operates. It reveals the data that was trapped, the information gleaned from the data, and the information users need to remediate the issue quickly.
Data quality rules and remediation steps go hand in hand. Everything in proactive data quality must be tracked and transparent so data teams can provide evidence of value to leadership.
Fit-for-consumption
Fit-for-consumption data quality implementation requires users to write several rules that anticipate quality issues in data that arrives from a third party. Using a dedicated tool, it's possible to automate scoring for specific datasets, further strengthening your data quality dimensions.
Anomaly detection
For anomaly detection, you need an automated AI/ML tool that can detect anomalies in your systems. This approach supports continuous improvement and ties into your overall data quality implementation plan.
Measuring the Impact of Data Quality
As we've mentioned, data quality implementation needs executive buy-in. Everyone in an organization must feel invested in improving the data landscape, especially the executives charged with allocating funding to these initiatives. Measuring impact is a key way of encouraging this.
Data teams must report all adverse data events that have impacted users every month. The report should include the events that have been remediated and those where work is still ongoing, the number of users impacted, how many people it took to fix the issue, the cost to the business, and information about root cause analysis.
These reports can be used at the end of the year to explore numerous factors. For example, vendors that should be avoided or ETL systems that are underperforming.
How OvalEdge Enables Data Quality
OvalEdge is a comprehensive data governance tool that addresses metadata governance, data quality, data access, and compliance. Ultimately, our platform includes all of the features required to implement each of the four aspects of data quality we have covered in this blog.
Related Case Study: Improving Data Quality at a Regional Bank
For reactive data quality, OvalEdge provides a data catalog where any user in an organization can report a data quality issue. Each issue is assigned to a data steward so appropriate action and remediation steps can be undertaken. This complete workflow is out of the box.
For proactive data quality, OvalEdge comes with pre-configured, customizable data quality rules and features that enable teams to write their own rules using SQL. We make it easy for users to write remediation steps and assign data stewards to quickly implement proactive data quality procedures. Alerts and the entire workflow are automated.
Fit-for-consumption measures are implemented through rules that can be written on any file or system, or through the option to use rules recommended by OvalEdge. We also provide data quality scores for every file in a system, third-party or otherwise, enabling users to identify data quality issues while committing a lot of processing power.
Regarding anomaly detection, OvalEdge has a dedicated feature that utilizes AI/ML to identify a data quality issue and report it to a company’s IT department. Individuals are assigned to a specific schema and receive alerts when an issue is detected in their area. From this point, they can follow remediation steps to fix the issue.
OvalEdge also has an advisory service and a dedicated Data Governance Academy to help train users on how to take appropriate actions to support data quality improvement and many other related tasks.
FAQs on Data Quality Implementation
-
What are the key data quality dimensions?
The main data quality dimensions include accuracy, completeness, consistency, timeliness, validity, and uniqueness. Together, they form the foundation of a successful data quality management strategy.
-
What is a data quality implementation plan?
A data quality implementation plan outlines the steps, processes, tools, and stakeholders involved in maintaining data accuracy and consistency across systems.
-
Why are data quality dimensions important?
Data quality dimensions help organizations evaluate the reliability and usability of their data for analytics, compliance, and decision-making.
-
How do you measure the success of a data quality implementation plan?
Success can be measured through metrics like the number of data quality issues identified, time to resolution, business impact, and improvements in accuracy or completeness scores
-
What tools can help with data quality implementation?
Platforms like OvalEdge automate rule-based validation, anomaly detection, and data quality scoring, ensuring continuous improvement across all data quality dimensions.
Deep-dive whitepapers on modern data governance and agentic analytics

OvalEdge Recognized as a Leader in Data Governance Solutions

.png?width=1081&height=173&name=Forrester%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.