
DATA LINEAGE
Visualize Your Data Flow Effortlessly & Automated
TRUSTED BY CUTTING EDGE COMPANIES TO VISUALIZE THEIR DATA FLOWS
.png?width=512&height=139&name=unnamed%20(8).png)
.png?width=202&height=66&name=ferratum(1).png)

.png?width=284&height=100&name=naranjax%20logo%20(1).png)
Data Team
Impact
Analysis
Understand your complex data pipeline and proactively assess the impact of a change, and communicate with the right people.

Business Team
Build
Trust
Transparency and clarity build trust. Provide your business team with a clear picture of how the data is being used and transformed.
Compliance Team
Track
Data
Automated lineage means you can uncover upstream data to the point of origin. You never have to run the risk of your reports failing to qualify.
System
Object
Attribute
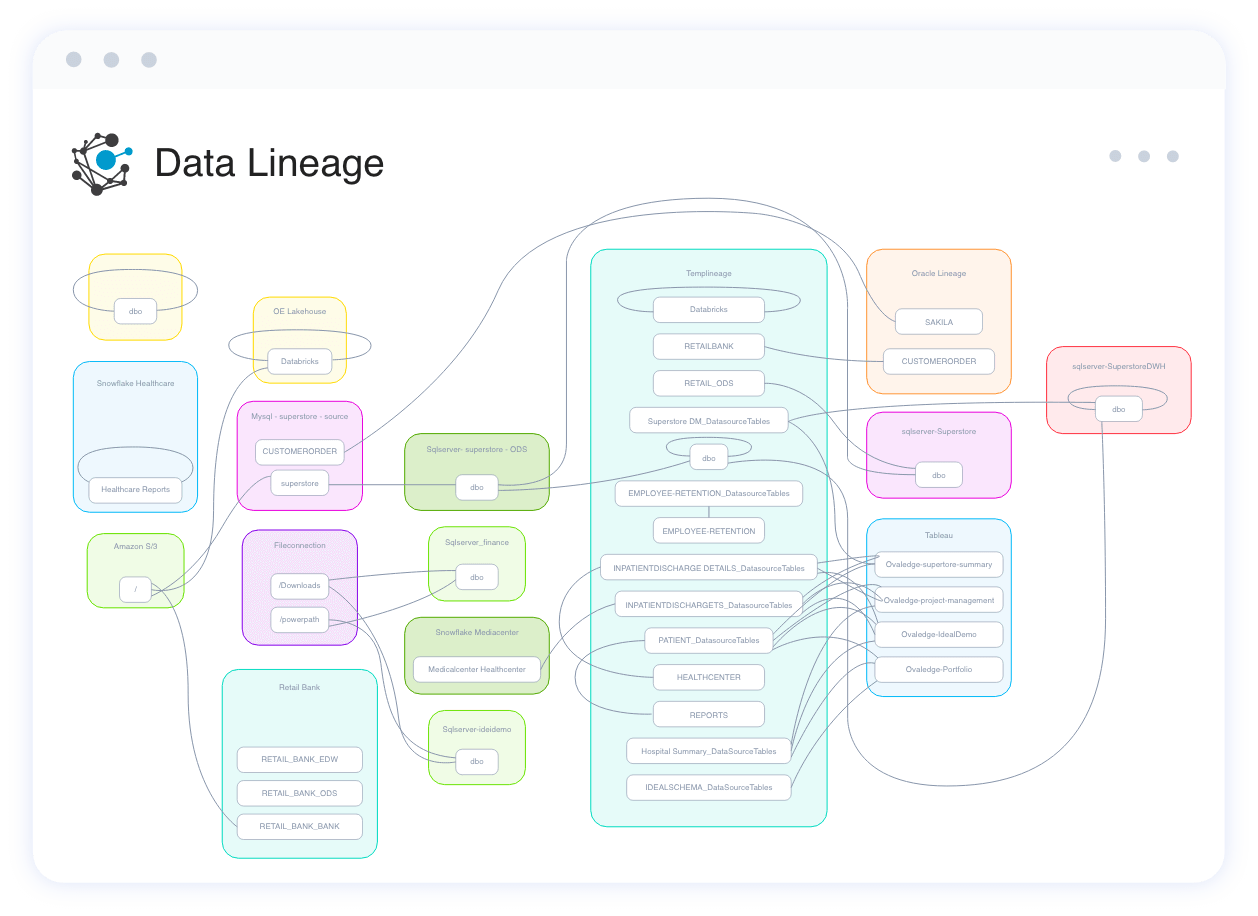
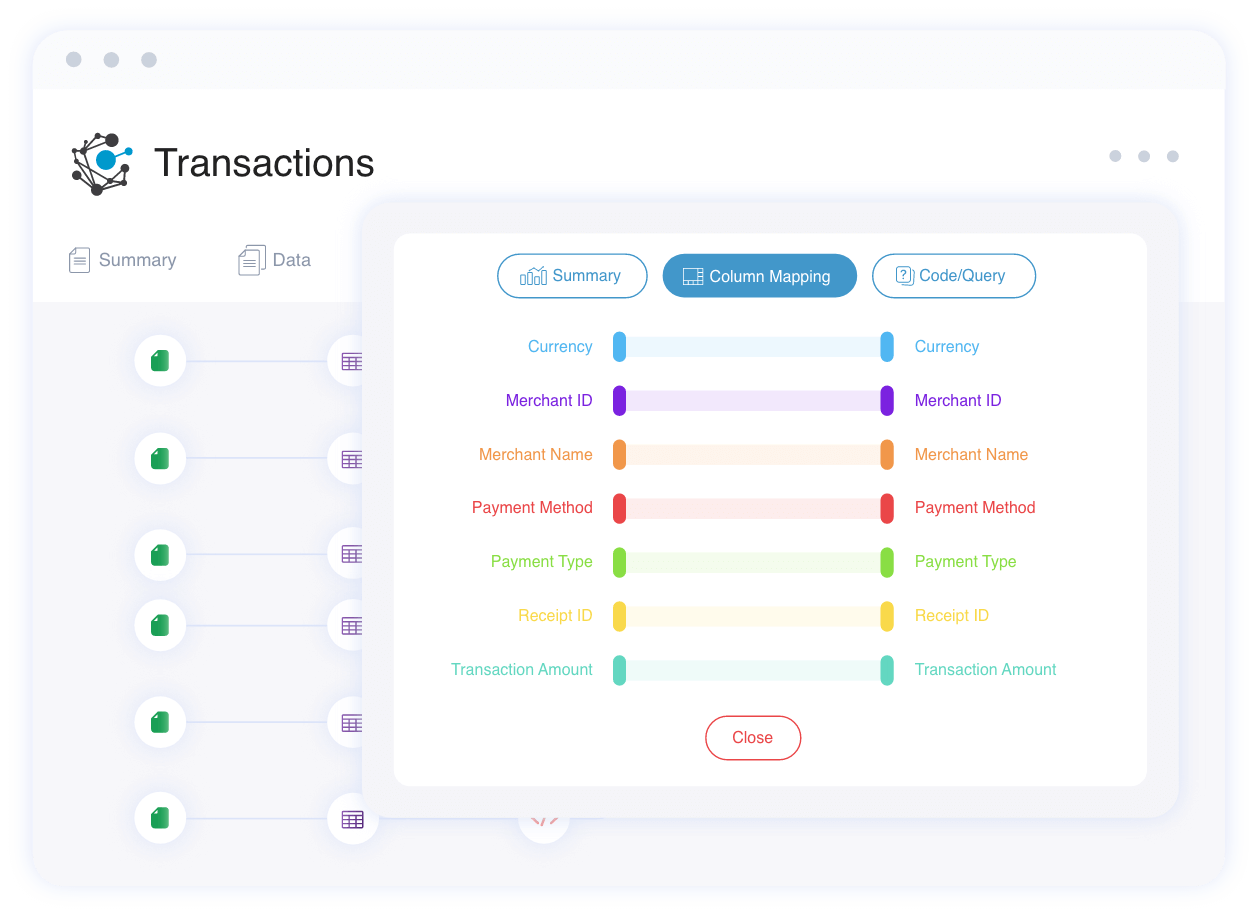
Get a Bird's Eye View in a Snap
View the data flow between various applications, warehouses, and reporting systems with one click.
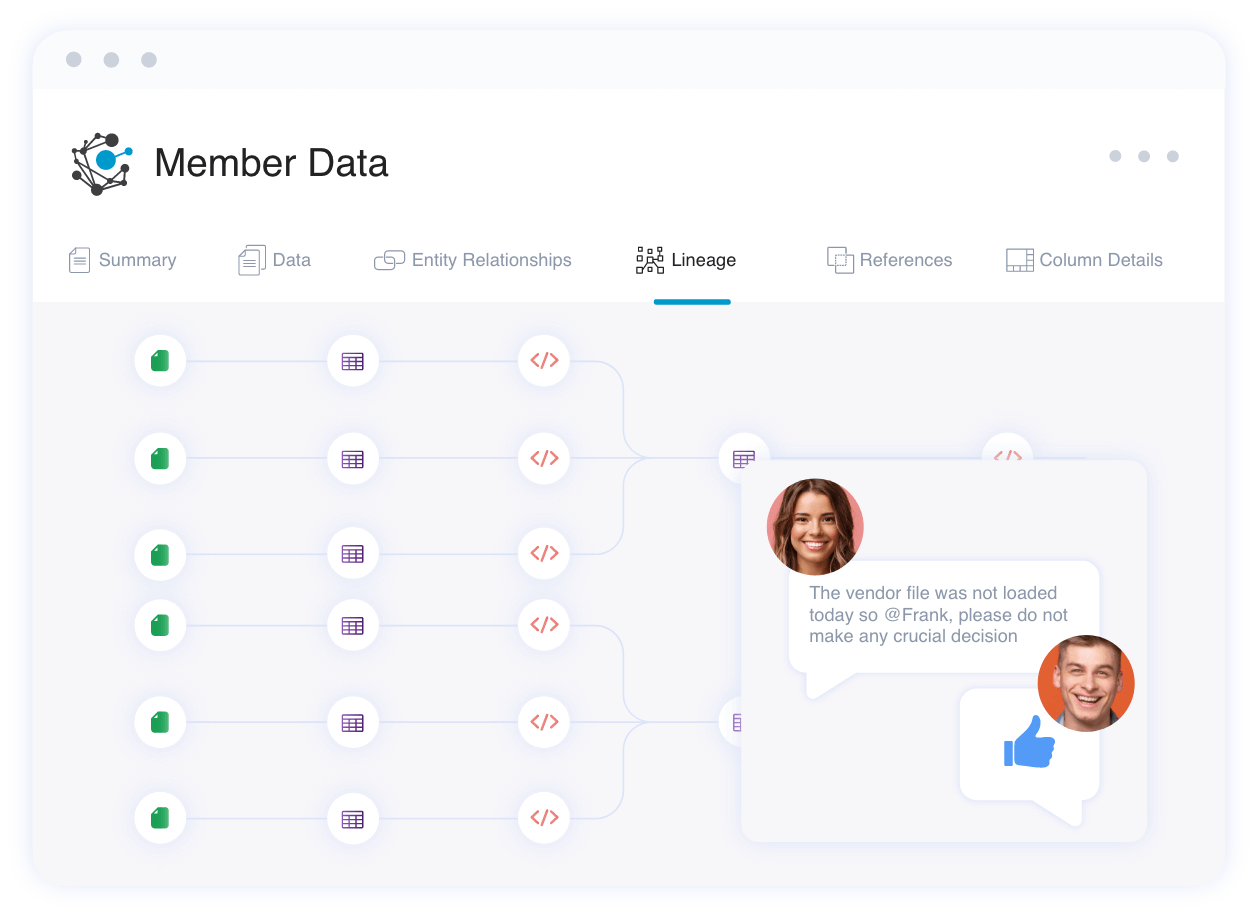
Collaborate with right stakeholders
Object level lineage connects the dots, and you can reach to the right person and collaborate within context.
Do connected governance
Object level lineage connects the dots, and you can reach the right person and collaborate within context.
Analyze upstream for business term discussion
Bring the right people together for conflict resolution and consensus building.
Analyze downstream to assess impact of any change
Proactively analyze which reports might fail or report inaccurate data when upgrading your source systems.

