


Until recently, data lakes were the hot thing in data architecture, but more and more companies are turning away from this approach in search of an alternative.
This is because organizations using this centralized approach have found that it’s inefficient due to the over reliance on dedicated data teams. Not only did this cause bottlenecks, but it also caused problems, because it’s impossible for a data team to know and understand every team's needs.
In fact, Gartner reported that 80% of organizations seeking to scale digital business between now and 2025 will fail because they don’t take a modern approach to data and analytics governance.
For many in the industry, the alternative of choice is Data Mesh, a new architecture that could well be the solution.
There are already some fantastic resources available on the topic, but we wanted to give you a summary, and explain where OvalEdge fits in.
If you want to know more about implementing Data Mesh, or want to see how OvalEdge can help, schedule a demo here.
What is Data Mesh?
As with any new concept or technology, the first thing we need to know is what Data Mesh actually is? It’s only a couple years old, so resources are scarce. But as it was created by Zhamak Dehghani at ThoughtWorks, it makes sense to kick things off with their definition:
Data Mesh is an analytical data architecture and operating model where data is treated as a product and owned by teams that most intimately know and consume the data.
This is a good high-level definition, and it introduces the core concept that data ownership should be decentralized.
To help achieve this, there are four principles of Data Mesh:
- Domain Ownership
- Data as a product
- Self-serve data platforms
- Federated computational governance
These principles form an architecture that can be applied across your business, helping avoid bottlenecks and creating shared ownership.
But before we delve further into these principles, it’s important to first talk about what Data Mesh isn’t.
- It isn’t something that can be implemented by a single person
- No single tool can generate or implement a ‘mesh’
- It’s not a silver bullet that will magically fix all your data issues
It’s an alternative approach to get value from data, based on how you share data, structure your teams, and carry out data governance. Decentralization is at the heart of it, and if implemented well, your data can be used for much more than just BI reports.
It’s called a ‘mesh’ because teams can access data products created and owned by other teams, creating a network of data that benefits everyone.
What are the benefits of implementing Data Mesh?
As I explained at the start of this article, the reason people are turning away from data lakes is because it creates bottlenecks. And because you effectively end up with a small group dictating data policy and structure to a whole company without knowing their wants and needs.
Data Mesh directly removes these issues by decentralizing the architecture, and allowing autonomy at the domain level.
This not only removes bottlenecks, but also removes most of the friction normally associated with data architecture and governance. Teams can make changes to their data products on their terms, and if there is an issue/query relating to another team's product, they can be directly approached.
It’s worth mentioning though that if your current architecture works for you, switching to Data Mesh won’t magically make everything even better.
These benefits largely relate to organizations who currently struggle with data lakes, or are in the process of planning their approach and architecture.
Data Mesh Principles and Architecture
As mentioned above, the Data Mesh architecture is built on four principles. This makes it easier to analyze your own architecture, and work towards creating your own Data Mesh.
They all have their own stand-alone merits, but you won’t see the full benefits of the Data Mesh architecture without adhering to all four.
Domain ownership
The first principle will also require the biggest cultural upheaval within your company. Instead of a central data team owning all the data, each domain team takes full responsibility for their domain's data.
This decentralized approach not only removes the reliance on dedicated data teams, but also removes friction between the team member and the data they need day-to-day.
For example, if George from marketing needs data on how the website performs, they no longer need to raise a request for that data.
Similarly, if developer Maggie is trying to diagnose a bug in their software, they can look directly at the affected data, rather than wait for someone to look at it for them.
Because analytical and operational data ownership has shifted to the domain teams, though, George and Maggie now have an increased responsibility to monitor the data and maintain the quality.
Speaking of which…
Data as a product
The next Data Mesh principle requires a shift in how you view your data. Instead of seeing it as a resource you use, it needs to become a product in its own right. A product that can be accessed and used by other domain teams.
Similar to how you would treat a public-facing API, your data should be easily accessed, and organized in a way that is both clear and logical.
If Maggie needs to access some marketing data for their project, George and their team should ensure this is as simple as possible. Maggie is a consumer in this scenario, and shouldn’t need to jump through hoops to get what they need.
Treating data as a product means domain teams have to plan for ‘consumers’, and structure their data to facilitate this. This is a new layer of accountability that hasn’t been there before, and can take time to implement.
Self-serve data platforms
The previous two principles have clear benefits, but also raise big questions about how you’ll afford to train these domain teams to do all this? Surely the time and money it costs will outweigh the positives!
It’s a valid question. It would be very expensive to teach everyone the skills to build their own architecture. Especially an architecture that facilitates creating, deploying, executing, and monitoring data products.
This is where the third principle comes in.
Instead of expecting everyone to learn these skills, you have a domain-agnostic team focused on configuring and maintaining a data platform the other teams will use.
This self-serve data platform is there to make it as simple as possible for domain teams to build their data products to a high standard. Essentially, it removes friction while enabling domain autonomy across teams.
This way, Maggie and George don’t need to be experts in building data architectures, they just need to be adept at using the data platform provided to them.
Federated computational governance
While decentralization is at the heart of Data Mesh, to maintain consistency and quality, there still needs to be global standard policies that apply across the teams.
This is solved in this architecture with the final principle — federated computational governance.
To achieve this, you need to assemble a group of domain data product owners and data platform product owners from across the domain teams. These individuals are responsible for creating and communicating global policies and standards.
The goal is to ensure interoperability between teams, while maintaining decentralization at the domain level.
This prevents Maggie and George from creating their data products to different standards, creating confusion and friction when someone uses them.
Data Mesh Logical Architecture
It’s a decentralized approach that enables domain teams to perform cross-domain data analysis using self-service. The domain is at the heart of the system, along with its responsible team and its operational and analytical data. The domain team builds data models to analyze operational data. It then uses this analytical data to build data products based on other domains’ needs.
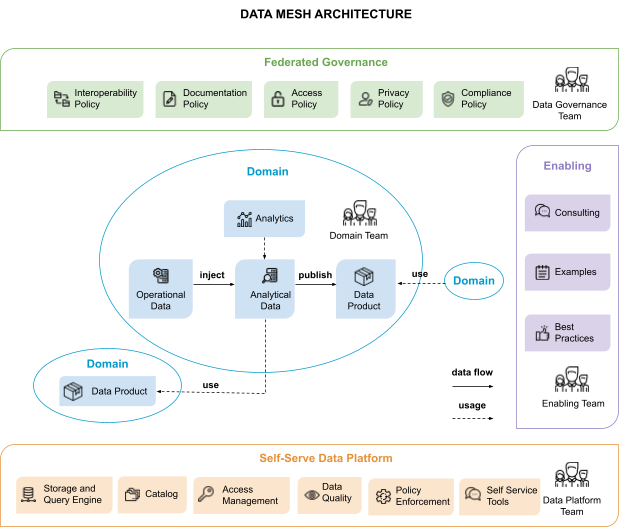
Teams agree on global policies, including interoperability, security, and documentation standards. They do this as part of a federated governance guild, so they can discover, understand, and use data products in the mesh. With the domain-agnostic data platform provided by the data platform team, domain teams can easily create their own products and perform their own analyses. It is the responsibility of an enabling team to guide domain teams on how to model analytical data, use the data platform, and build and maintain interoperable data products.
How do you create a Data Mesh using OvalEdge?
As much as we’d love to say you can simply install the Data Mesh plugin, and OvalEdge will do the rest for you, it’s not quite that simple. As I mentioned previously, this is an architecture, and can’t be solved by one tool. But OvalEdge can play a crucial role in solving the puzzle.
Here’s an example of how OvalEdge fits into your physical architecture:
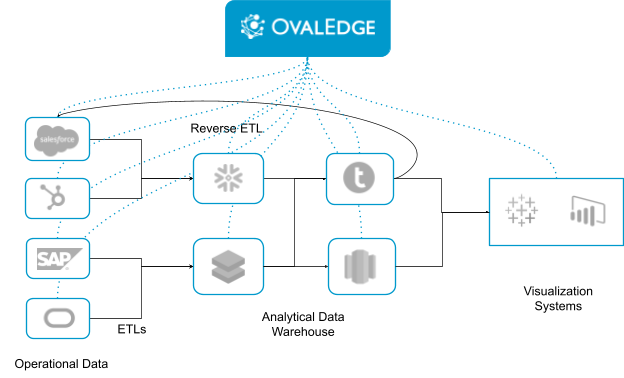
Establish Federated Governance and Control it
Governance is at the heart of everything OvalEdge does, so establishing federated governance for your Data Mesh is as simple as possible. OvalEdge is a unified platform with Data Catalog, Access Management and various kinds of policy enforcement.
Using OvalEdge, you can easily manage and control the following policies.
- Privacy policies, which are dictated by various regulations like GDPR and CCPA
- Documentation policies, compliant with regulations like BCBS in the banking sector, and SOX for all public companies.
- Establish policies for confidential data.
- Establish locationality policy, which is dictated by locationality laws.
- Establish policies for secret data
- Standardization & documentation policies
Then once they’re established, you can monitor and control these policies within OvalEdge.
Build a self-service platform
Data Mesh doesn’t work unless everyone can find the data they need. OvalEdge makes it easy to build your own self-service platform. You can configure many data sources, and use it in a number of ways:
- Data Catalog: which allows everyone to easily find and understand the data at scale.
- Data Access Management: this allows you to maintain security, while also allowing end-users to access data from other domains using an approval process.
- Business Glossary: this allows you to standardize your documentation and apply it across the data.
- Collaborate on data with the right context.
- Analyze data using various tools like Querysheet and other third-party tools.
Establish Domain-based Teams
As we’ve discussed, splitting people into domain teams is a key part of Data Mesh. Once you’ve decided what these teams are, you can simply organize them into teams within OvalEdge. We also provide various ways to organize teams, by roles, by teams, etc.
This helps you assign people the right privileges, and make changes to the configuration in bulk.
Divide Data into Domain
Once you have your data sources and governance set up, you can divide your data into domains that match your team structure.
Following traditional data governance, you can ensure everyone has access to the data they need, while remaining compliant in every market you’re in.
Build new Data Products
Now your teams can work to create their data products, and start creating value for each other.
Working together in OvalEdge, it’s easy to organize the data into meaningful products, and share them.
Share & Collaborate
Colleagues can then share and collaborate on their data products within OvalEdge. Whether that’s within their domain team, or across teams.
At this point, you have the makings of an effective Data Mesh, where teams own and maintain their own data products. And teams can easily use each other's products to work towards a shared goal.
Integrate
When used alongside a data storage provider like Snowflake, OvalEdge is the perfect platform for managing your decentralized data across your domain teams.
We manage your orchestration layer, including data governance and data analytics. Another key part of OvalEdge is the Data Catalog. This brings all your datasets together, allowing you to mesh them, create relationships, etc.
Now, I’m not going to sit here and insist that you need OvalEdge if you want to implement an effective Data Mesh architecture.
But what I can say is that we make it a whole lot easier!
What you should do now
|
Download Our Trending White Papers



