Reliable data is essential for accurate analytics and confident decision-making. A structured data quality management framework helps organizations enforce standards, monitor data continuously, and resolve issues proactively. With strong governance, automation, and lifecycle-based improvement, enterprises can maintain trustworthy data, reduce risk, and support scalable analytics and AI initiatives.
Imagine being a pilot whose navigation system is fed with inaccurate data. You might fly in the wrong direction or worse, crash. Similarly, poor data quality leads to incorrect conclusions, poor decision-making, and lost opportunities.
According to IBM, poor data quality costs the U.S. economy around $3.1 trillion annually. Data scientists spend most of their time cleaning datasets instead of analyzing them. And when data is cleaned later in the pipeline, it introduces assumptions that can distort outcomes.
The best practice? Address data quality at the source, not downstream.
What is Data Quality Management Framework?
A Data Quality Management Framework is a structured approach that organizations use to ensure their data is accurate, complete, consistent, timely, and reliable across its lifecycle. It provides a formal set of policies, processes, standards, roles, and technologies that work together to measure, monitor, and improve data quality across systems and business domains.
Instead of treating data quality as a one-time cleansing activity, the framework establishes continuous controls and governance so that data remains trustworthy as it is created, transformed, and consumed. By implementing a data quality management framework, organizations can systematically detect issues, enforce quality rules, and maintain high-confidence data for analytics, reporting, and operational decision-making.
Key Components of Data Quality Management Frameworks
A robust data quality management framework is built on several foundational components that work together to ensure data remains accurate, consistent, and trustworthy throughout its lifecycle. These components provide the structure needed to assess, monitor, and continuously improve data quality across the enterprise.
1. Data Profiling and Assessment
Data profiling examines datasets to understand their structure, patterns, anomalies, and overall health. This step helps organizations establish baselines, identify data issues early, and prioritize quality improvement efforts.
2. Data Quality Rules and Validation
Organizations define business rules and validation checks to ensure data meets required standards. These rules may include format checks, completeness thresholds, referential integrity, and business logic validations that run across data pipelines.
3. Continuous Monitoring and Alerts
Ongoing monitoring ensures that data quality is maintained in real time or near real time. Automated alerts notify stakeholders when data deviates from defined thresholds, enabling faster detection and response to issues.
4. Issue Management and Remediation
A structured workflow is essential for logging, tracking, prioritizing, and resolving data quality issues. Effective remediation processes ensure problems are not only fixed but also prevented from recurring.
5. Data Governance and Stewardship
Clear ownership and accountability are critical. Data stewards, owners, and governance teams define standards, enforce policies, and oversee quality initiatives to maintain organizational alignment.
6. Reporting and Data Quality Scorecards
Dashboards and scorecards provide visibility into data health through metrics, trends, and KPIs. These insights help business and technical teams measure progress and drive continuous improvement.
7. Automation and Scalability
Modern frameworks emphasize automation to handle growing data volumes and complexity. Platforms like OvalEdge help organizations scale data quality efforts by integrating profiling, rule management, monitoring, and governance into a unified environment.
Data Quality Management Framework Implementation Strategies
Implementing a data quality management framework requires a structured, business-aligned approach that ensures data remains accurate, consistent, and trustworthy at scale. The following implementation strategies help organizations operationalize data quality management effectively while supporting modern data environments.
1. Assess the Current State of Data Quality
Begin by conducting a comprehensive data quality assessment across critical data domains and systems. Use data profiling to identify gaps in accuracy, completeness, consistency, and timeliness. Establish baseline data quality metrics and document high-risk data assets. This step ensures your data quality management framework is built on real, measurable insights rather than assumptions.
2. Define Clear Data Quality Standards and Rules
Develop standardized data quality rules aligned with business requirements and regulatory needs. Define validation thresholds, acceptable error rates, and business logic checks for key datasets. Well-defined data quality standards create consistency across teams and form the foundation of a scalable data quality management framework.
3. Establish Data Ownership and Stewardship
Assign clear roles such as data owners, data stewards, and governance stakeholders. Define accountability for monitoring, issue resolution, and policy enforcement. Strong ownership models ensure the data quality management framework is embedded into day-to-day operations rather than treated as a one-time initiative.
4. Implement Automated Data Quality Monitoring
Automation is critical for maintaining reliable data systems. Deploy continuous data quality monitoring across pipelines, warehouses, and source systems. Automated alerts and anomaly detection help teams identify data issues early, reduce manual effort, and improve trust in enterprise data.
5. Integrate Data Quality into the Data Pipeline
Embed data quality checks directly into ETL/ELT workflows, streaming pipelines, and data ingestion processes. Shift-left validation prevents bad data from propagating downstream. A modern data quality management framework should support both batch and real-time data environments.
6. Establish Data Quality Metrics and SLAs
Define measurable KPIs such as data quality score, error rate, freshness, and rule pass percentage. Align these metrics with business outcomes and create data quality SLAs for critical datasets. Tracking performance through scorecards helps demonstrate the ROI of the data quality management framework.
7. Build a Closed-Loop Issue Management Process
Create workflows to log, prioritize, investigate, and remediate data quality issues. Root-cause analysis should be part of the process to prevent recurrence. A closed-loop remediation model ensures continuous improvement and strengthens long-term data reliability.
8. Enable Continuous Improvement and Governance
Data quality management is not a one-time project—it is an ongoing discipline. Regularly review rules, thresholds, and monitoring coverage. Align the framework with evolving business needs, new data sources, and regulatory requirements. Mature organizations treat data quality as a continuous lifecycle capability.
9. Leverage Automation and AI for Scale
As data volumes grow, manual approaches become unsustainable. Incorporate intelligent automation, anomaly detection, and rule recommendations to scale the data quality management framework efficiently. AI-driven monitoring can significantly improve issue detection and reduce operational overhead.
Benefits of Data Quality Management Frameworks
Implementing a data quality management framework delivers measurable business and technical advantages by ensuring data remains accurate, consistent, and trustworthy across the enterprise. Organizations that invest in a structured framework can improve decision-making, reduce risk, and maximize the value of their data assets.
1. Improves Data Accuracy and Reliability
A data quality management framework establishes standardized rules and continuous monitoring, which significantly reduces errors, duplicates, and inconsistencies. This ensures that business users and analytics teams can rely on high-quality data for reporting and operations.
2. Enables Better Business Decision-Making
When data is trustworthy, leaders can make faster and more confident decisions. High-quality data supports advanced analytics, AI initiatives, forecasting, and strategic planning, helping organizations respond quickly to market changes.
3. Reduces Operational Risk and Compliance Issues
Poor data quality can lead to regulatory violations, reporting errors, and financial risk. A structured data quality management framework helps enforce governance policies, maintain audit trails, and ensure compliance with industry and regulatory requirements.
4. Enhances Data Governance and Accountability
By clearly defining data ownership, stewardship, and quality standards, the framework strengthens enterprise data governance. It creates transparency around who is responsible for data health and ensures consistent policy enforcement across domains.
5. Increases Operational Efficiency
Automated data quality checks and monitoring reduce manual data cleansing efforts and rework. Teams spend less time fixing data issues and more time generating insights, improving overall productivity and lowering operational costs.
6. Supports Scalable Data and AI Initiatives
Modern analytics, machine learning, and AI systems depend on high-quality data. A robust data quality management framework ensures that growing data volumes and complex pipelines remain reliable, enabling organizations to scale innovation with confidence.
7. Improves Customer Experience
Accurate and consistent customer data leads to better personalization, targeted marketing, and smoother customer interactions. High data quality helps eliminate duplicate records, incorrect communications, and service errors.
8. Provides Measurable Data Quality Visibility
Dashboards, scorecards, and KPIs built into the framework give stakeholders clear visibility into data health. This transparency helps organizations track progress, prioritize improvements, and demonstrate the ROI of data quality initiatives.
Read more: What is Data Quality? Dimensions & Their Measurement
.png?width=629&height=398&name=unnamed%20(4).png)
Click the image above to download the Data Quality Assessment Tool.
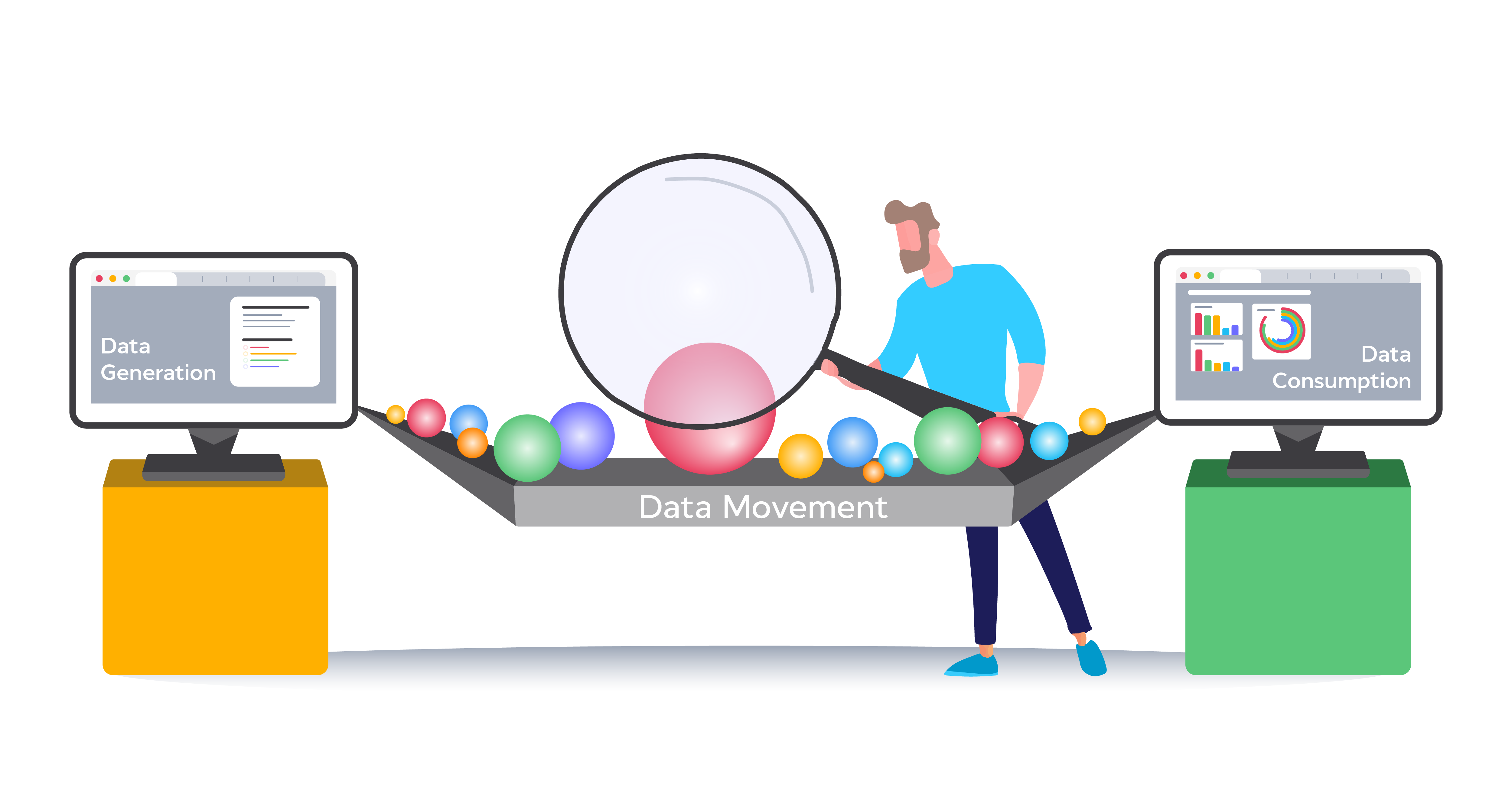
Scope of Data Quality Management
Before improving data quality, it’s crucial to understand where it can go wrong. A comprehensive data quality framework considers three key phases:
1. Data Generation
Data originates from multiple sources CRMs, ERPs, sensors, servers, and marketing platforms. Data from systems like ERP or CRM tends to be more critical. The goal is to ensure high-quality data at the source, supporting decision-making and operational efficiency.
2. Data Movement
Data moves between applications for business processes and reporting. Common movement methods include:
- Integrations: Through APIs or transactions
- Data pipelines: Bulk transfers between systems
- Manual processes: Manual entry or uploads
Without proper controls, integrations can move poor-quality data downstream.
3. Data Consumption
Once analyzed and consumed, data fuels marketing, forecasting, and analytics. If inaccurate or incomplete, it leads to poor insights and lost business opportunities. Effective data quality management tools ensure clean, validated data reaches the point of consumption.
Challenges of Data Quality Management Frameworks
Even with good intentions, several systemic issues cause data quality degradation:
1. Weak System and Business Controls
Applications often lack validation checks. For instance, an email field may only verify format, not validity. Business-level validation (e.g., sending a confirmation email) ensures true accuracy.
2. Inconsistent Data Capture by Machines
Sensors and systems often collect data inconsistently due to missing definitions or a lack of customizable controls.
3. Integrations Without Quality Checks
Most integrations prioritize data availability, not accuracy. As a result, bad data moves seamlessly between systems.
4. Fragile Data Pipelines
Pipelines often fail due to inconsistent schema design. Example: when a source field (120 characters) exceeds the target field limit (100), it causes breaks or truncation.
5. Duplicated Business Processes
When marketing, sales, and finance manage separate customer datasets, duplication and inconsistency become inevitable.
Understanding these causes helps define a targeted data quality improvement strategy tailored to your organization’s needs.
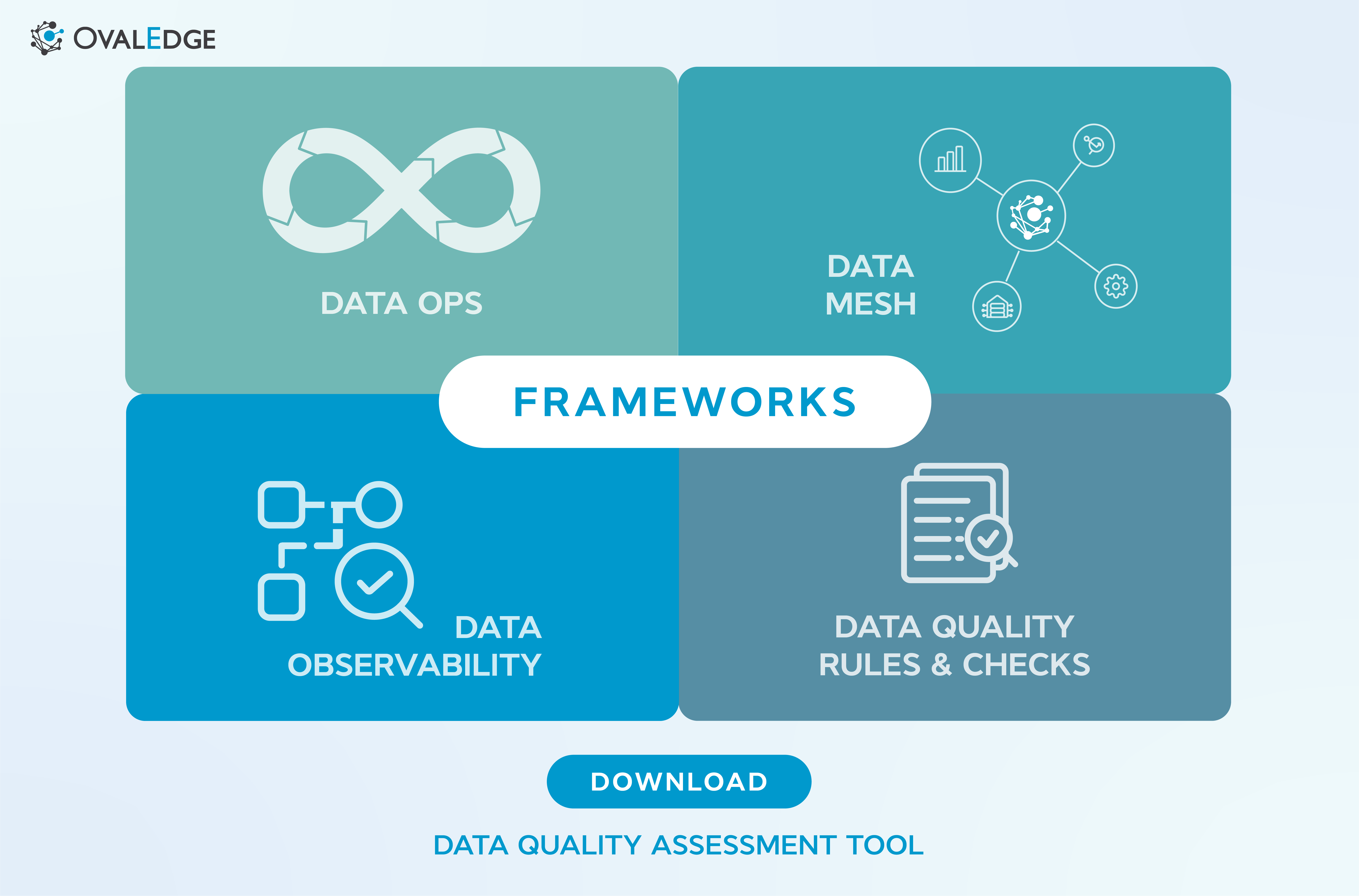
Different frameworks to manage data quality
Data quality is a multi-dimensional challenge, and no single framework can solve it all. Let’s explore some leading data quality management frameworks and approaches used by modern enterprises.
1. DataOps
DataOps applies DevOps principles to data management, improving collaboration and automation across teams. It streamlines the entire data lifecycle from collection and storage to analysis and reporting, ensuring efficiency and traceability.
2. Data Observability
This approach tracks data pipeline performance and system health. By analyzing operational metrics, data observability helps detect anomalies early and maintain reliability across systems.
3. Data Mesh
A Data Mesh decentralizes data ownership across teams, empowering them to manage their domains independently. It promotes autonomy while maintaining consistency through standardized governance policies.
4. Data Quality Rules and Checks
Automated data quality checks monitor accuracy, completeness, and consistency. They flag missing values, duplicates, or incorrect formats, allowing teams to take corrective action before problems spread.
No single approach fits all. The most effective data quality management framework combines multiple methodologies to meet unique organizational needs.
Why is data governance a must?
Despite the differences in focus, one common thing among all the frameworks mentioned above is the need for a unified governance structure. This structure ensures data is used and managed consistently and competently across all teams and departments.
A federated governance or unified governance approach can help ensure data quality, security, and compliance while allowing teams to work independently and autonomously.
As we mentioned at the start, data quality is one of the core outcomes of a data governance initiative. As a result, a key concern for data governance teams, groups, and departments is improving the overall data quality. But there is a problem: coordination.
The data governance and quality team may not have the magic wand to fix all problems. Still, they are the wizards behind the curtain, guiding various teams to work together, prioritize, and conduct a thorough root cause analysis. A common-sense framework they use is the Data Quality Improvement Lifecycle (DQIL).
To ensure the DQIL's success, a tool must be in place and include all teams in the process to measure and communicate their efforts back to management. Generally, this platform is combined with the Data Catalog, workflows, and collaboration to bring everyone together so that Data Quality efforts can be measured.
Data Quality Improvement Lifecycle (DQIL)
The Data Quality Improvement Lifecycle (DQIL) is a framework of predefined steps that detect and prioritize data quality issues, enhance data quality using specific processes, and route errors back to users and leadership so the same problems don’t arise again in the future.
The steps of the data quality improvement lifecycle are:
- Identify: Define and collect data quality issues, where they occur, and their business value.
- Prioritize: Prioritize data quality issues by their value and business impact.
- Analyze for Root Cause: Perform a root cause analysis on the data quality issue.
- Improve: Fix the data quality issue through ETL fixes, process changes, master data management, or manually.
- Control: Use data quality rules to prevent future issues.
Overall data quality improves as issues are continuously identified and controls are created and implemented.
Learn more about Best Practices for Improving Data Quality with the Data Quality Improvement Lifecycle
Why You Need the Right Data Quality Management Tools
Implementing a data quality framework at scale requires robust tooling to automate validation, enforce rules, and track performance.
A good data quality management tool should:
- Automate profiling, validation, and issue detection.
- Integrate seamlessly with your data catalog or warehouse.
- Support collaboration and workflow automation.
- Offer dashboards for tracking quality metrics.
At OvalEdge, we bring all these capabilities into one unified platform, enabling organizations to catalog, govern, and improve data quality from source to consumption.
Our platform supports DQIL-based workflows, automated data quality rules, and real-time monitoring for continuous improvement.
Wrap up
So, you now know where and why bad quality data can occur, emerging frameworks to manage data quality, and the data quality improvement lifecycle to manage all the data quality problems.
But one important thing is to socialize the data quality work inside the company so that everyone knows how we are improving the data quality.
At OvalEdge, we can do this by housing a data catalog and managing data quality in our unified platform. OvalEdge has many features to tackle data quality challenges and implement best practices. The data quality improvement lifecycle can be wholly managed through OvalEdge, capturing the context of why a data quality issue occurred.
Data quality rules monitor data objects and notify the correct person if a problem arises. You can communicate to your users which assets have active data quality issues while the team works to resolve them.
Track your organization’s data quality based on the number of issues found and their business impact. This information can be presented in a report to track monthly improvements to your data’s quality.
With OvalEdge, we can help you achieve data quality at the source level, following best practices, but if any downstream challenges exist, our technology can help you address and overcome them.
FAQs
- What is a data quality management framework?
It’s a structured approach that defines processes, tools, and roles to ensure data accuracy, completeness, and reliability throughout its lifecycle. -
What are common challenges in managing data quality?
Inconsistent capture, lack of validation controls, duplicate records, and siloed processes are the biggest hurdles organizations face. -
How does data governance support data quality management?
Data governance defines standards, ownership, and accountability ensuring all teams maintain consistent data quality practices. - What tools are used for data quality management?
Tools like OvalEdge, Talend, and Informatica help automate validation, profiling, and monitoring, forming the backbone of any robust data quality improvement strategy.
Deep-dive whitepapers on modern data governance and agentic analytics

OvalEdge Recognized as a Leader in Data Governance Solutions

.png?width=1081&height=173&name=Forrester%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
.png?width=1081&height=241&name=KC%20-%20Logo%201%20(1).png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.